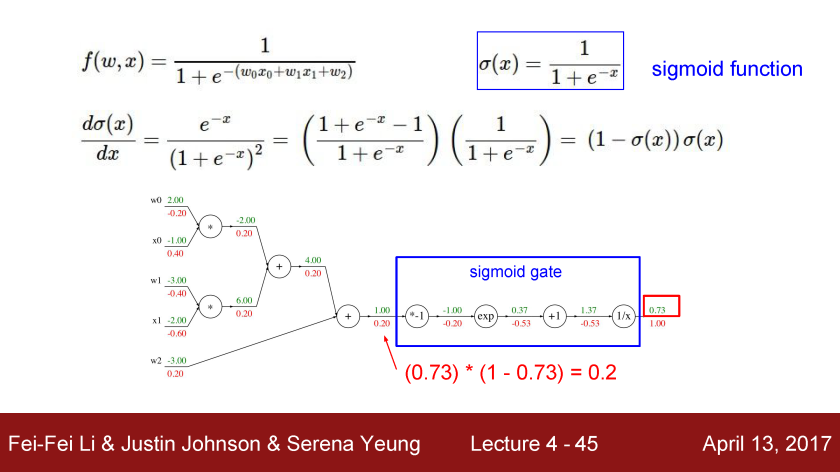
위 팁과 더불어 sigmoid gate를 사용한다면 계산 과정을 더욱 압축할 수 있습니다.
e^-x에서 x 만큼의 연산을 t로 치환하여 해당 연산까지 묶어 f의 결과값과 1에서 그 결과값을 뺀 값 사이의 곱으로 계산할 수도 있습니다.
위 팁과 더불어 sigmoid gate를 사용한다면 계산 과정을 더욱 압축할 수 있습니다.
e^-x에서 x 만큼의 연산을 t로 치환하여 해당 연산까지 묶어 f의 결과값과 1에서 그 결과값을 뺀 값 사이의 곱으로 계산할 수도 있습니다.
Jacobian matrix
local gradient와 더불어서 살펴보아야 할 개념인 Jacobian matrix에 대해 설명하겠습니다.
Jacobian matrix은 local gradient * global gradient 연산을 할 때 필요한 matrix를 의미합니다.
행렬 간 곱 계산이 필요한 Jacobian matrix의 크기를 input, output dim의 크기와 비교하여 살펴보겠습니다.
input 과 output의 크기가 4096 크기라고 할 때, Jacobian matrix크기는 4096 * 4096입니다. max연산이 진행되어 0과 x 의 크기 비교를 위해 일부 0으로 채워진 칼럼이 필요하기 때문입니다. (자세한 설명 추가하기) 이때, 이전 3장에서 살펴본 minibatch 개념을 적용하겠습니다. 이 경우, 열과 행에 각각 minibatch 크기가 곱해져야 가능합니다.
Neural Networks
다음은 뉴런 네트워크에 대해 알아보겠습니다.
뉴런 네트워크는 기존 선형 분류기를 층을 쌓아 여러겹의 층으로 구성된 분류기를 만드는 데에서 시작합니다. h는 hidden layer로서 칼럼을 추출하는 역할을 맡습니다. 위 모형은 3072의 input data x 에 대해 W1가 적용된 연산을 진행하여 100개의 칼럼을 추출한 후, W2 을 가중하여 연산을 통해 최종 10개의 class에 대한 확률이 계산됩니다.
뉴런의 방식과 비슷하게 연산이 진행됩니다. 이때 f에 대해 활성함수가 사용되는데 일반적인 활성함수는 sigmoid 입니다. sigmoid는 0과 1 사이 값을 갖기 때문에 각 class의 score를 표시하기 적합합니다.
이 외에도 다양한 활성함수가 존재합니다. 요즈음은 ReLU를 기본적인 활성함수로 사용하는 추세입니다.
3-layer의 분류기 모형을 수도코드로 나타내면 다음과 같습니다(layer 개수를 셀 때 input layer은 제외합니다).
SVM은 2,3차원 이상의 고차원인 초평면(hyperplane)에서 결정경계를 기준(Decision boundary)으로 데이터를 분류한다. 이떄 결정 경계와 인접한 데이터 포인트를 Support Vectors,이 서포트 벡터와 Decision boundary간의 거리를 Margin이라 한다. SVM은 허용 가능한 오류 범위 내에서 가능한 최대 마진을 만들어야 한다. 이러한 SVM은 다항 분류에서도 사용하는데 이를 multiclsss SVM이라고 하며, 여기서 사용되는 loss funtion이 hige loss이다.
위 사진과 같이 고양이, 자동차, 개구리 세개의 클래스를 분류하 트레이닝 셋이 있다고 가정했을때,
각 각 class 별 점수를 보면, 고양이 경우 class cat보다 car 점수가 높다. 즉 잘못분류함을 알 수 있다
SVM 함수을 이용해서 loss function이 어떻게 계산되는지 과정을 구체적으로 살펴보면 다음과 같다.
(Xi, Yi) : xi가 이미지, yi가 레이블
score벡터를 f(xi,w) ,
Sj는 잘못된 레이블의 스코어, Sy는 재대로된 레이블의 스코어
1은 safty margin : decision rule 이 최소한 1보다는 큰 값을 주도록 한게 아닐까 싶다…
잘못된 레이블 스코어에서 제대로 된 레이블간 스코어 차에 일을 더한값이 영보다 크면 그 값이 loss가 되고
0보다 작으면 0이 레이블이 된다는 의미한다.
첫번쨰 고양이 이미지를 예를들면 Sj (5.1)에서 Syi (3.2)를 뺴고 1를 더하면 2.9 값을 얻게된다. 그리고 0과 비교시 2.9가 크므로 최대값은 2.9를 얻게 다. 그다음 또 잘못된 레이블 스코어(frog 점수)에서 맞는 레이블 스코어간의 차를 구하고 1를 더하면 -3.9를 얻게되는데 0과 비교시 0이 더크므모 max값은 0이된다. 그리고 처음에 구한 2.9와 0을 더해 최종 Li값은 2.9가 된다.
이런식으로 나머지 두개의 사진도 같은 방법으로 구한다음, 각 Li값을 합산하여 class 수 만큼 나누면 최종적으로 5.27의 값을 얻게된다.
여기서 알게된 사실 트레이닝 데이터에 대해서 분류가 잘 되지 않으면 loss function은 높고, 분류가 잘 될 경우에는 loss function이 낮음을 알 수 있습니다.
그리고 강의에서는 5가지 질문을 하는데, 각 질문을 통해 얻게된 것은 다음과 같다.
SVM은 데이터에 둔감하고, score 값이 중요한게 아니라 정답 클래스가 다른 클래스보다 큰지 작은지 중요하다.
loss의 최소값은 0이고, 무한대까지 최대값을 가진다. 또한 loss는 class 갯수-1 만큼 나온다.
그리고 우리가 구한 Weight가 uique 값인지 물어보는데, weight는 train set에 맞춰져 있기에, test에서는 trainning set에서 구한 weight와 다를 수 있다.
우리가 구한 train이 파란색이라고 가정했을 때, 초록색 네모는예측하지 못한 상황이 나오게 되는데, 즉 trainning에 맞춰져 test를 못맞춰 정확도가 아지는것을 과적합(overfitting)이라고 한다.
이러한 train 데이터에 과적합되는 결과를 막기 위해 정규화 항(regularization)을 추가해 사용한다.
L2 regularization을 진행하게 되면 가중치가 전반적으로 작고 고르게 분산된 형태로 진행되 과적합을 줄일 수 있고, test set에 대한 일반적인 성능을 향상시킬 수 있게 된다.
Soft Max
Multi class SVM이 score 값만 생각하여 분류했다면, softmax는 확률분포를 이용해 socre 자체에 의미를 부여 한다.
Softmax는 신경망 출력층에서 사용하는 활성함수로, 주로 분류문제에 사용된다.
구체적으로 점수 벡터를 클래스 별 확률로 변환하기 위해 흔히 사용하는 함수로 각 점수 벡터에 지수를 취한 후, 정규화 상수로 나누어 총 합이 1이 되도록 계산한다.
즉 입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수이다.
예를들어 사진속 인물의 표정을 확률적으로 수치화한다고 했을때, 슬픔은 11%, 웃음은 29%, 화남은 60% 로 나타났다면 같이 확률적으로 화난 표정에 가깝다고 분류하는 것이다.
연산 과정은 주어진 스코어에 대해 exp 연산을 취해 값을 구하고, 그 값을 모두 더한 값을 해당 클래스 스코어에 나눠준다. 마지막으로 -log 연산을 취해 최종 확을 계산한다.
지수 함수를 사용하면 가중치를 더 커지게 하는 효과를 얻을 수 있고, -log를 사용한 이유는 x축을 확률, y축을 loss 라고 생각했을 확률이 1에 가까워질수록 loss가 0에 가까워지기 때문에 -log를 사용한.
또한 강의에서 min,max 값에 대해 묻는데, – log 그래프를 생각하면 최소는 이론적으로 0,최대값은 무한대다.
optimization은 loss를 최소화 시킬 수 있는 weight를 찾는 것이다.대표적인 방법으로 random search와 gradientdescent가 있다.
random search는 w의 위치값을 무작위로 포인트를 찾는 방법이지만 예측의 정확도가 15%~95%로 불안정하다. 따라서 절대로 사용해서는 않다.
실질적 전략방법인 경사하강법(gradientdescent)은 경사를 따라 내려가는 방법이다.
1차함수인 경우 아래 식과 같이 함수을 미분하여 구하는데, 이렇게 수치적으로 경사를 구하는 방법을 numerical gradient라고 한다.다차원에 경우에는 vector형태로 나타나게 된다.
위와 같이 현재 weight가 구성되어 있고, loss값이 1.25347을 나타내고 있을 때, gradient dW를 구하기위 해 바로 앞에 lim f(x+h)-f(x)/h 수식을 이용하면 다음과 같다.
h를 0.0001으로 미세하게 지정한 후f(x+h)의 loss를 구하면 1.2532가 나오고 이둘의 차를 0.0001로 나눈 경사값은 -2.5를 얻었다. 기울기가 음수라는건 downward 즉 기울기가 w가 늘어나면 loss에 음에영향 을 준다는걸 의미한다.
두번째 차원에서 -1.11에 h( 0.00001)를 더한 loss 값이 1.25353으로 loss값이 조금 증가했다. downward와 같은 방법으로 구하면 경사값이 0.6이 나온다.이처럼 기울기가 늘어나면 upward의 영향을 가지고 있다고 의미한다.
세번째 차원의 예시를 면 , 0.78에 h를 더한 loss 값이 현재 weight와 동일하다. loss의 변화가 없는것은 기울기가 없다는 것이다. 이처럼 계산을 통해 기울기를 구하는 것을 numerical gradient라 한다.
그런데 미분을 통해 얻은 값은 정확한 값이 아닌 근사값을 구한 것인데, 값이 정확하지 않고 weight가 무수히 많을 경우 평가를 하기가 어렵고 값을 구하기에도 느릴 것이다.
우리가 원하는 것은 w가 변할때 Loss가 얼마큼 변하는지 알아보는 것인데 이는 미분을 통해 쉽게 구할 수 있다.
미분은 뉴튼과 라이프니츠가 고안한 방법으로, 미분을 통해 얻는 방법을 analytic gradient라 한다.
실제로 미분식을 이용하면 다음과 같이 편미분값들을 구할 수 있다.
정리해서 말하자면 numerical은 근사치이고 느리지만 반면에 코드로 작성하기 쉽다.
반 analitic은 빠르고 정확한데 코드로 작성시 에러가 늘어날 경우가 많다.
실제로는 analitic gradient을 쓰면 되고 계산을 정확하게 이뤄냈는지 검토과정에서 numerical 방법을 활용하면 된다. 이렇게 확인하는 방법을 gradient check라 한다.
이렇게 Gradient Descent를 코드로 구현하면 lossfunction, data, weight을 전달해줘서 gradient를 구한다. 구한 gradient에 stepsize(learing rate), 알를 곱해줘서 그것을 기존 weight에 증감하여 Parameter를 업데이트한다. 그리고 gradient 값만큼 weight를 감소시켜 주기 위해 앞에 마이너스를 붙인다.
그래서 이렇게 orignal의 weignt가 주어졌을때 음의 gradient방향으로 업데이트 해가면서 최적화을 해나가는것이 gradient decent가 되겠다.
이렇게 앞에서 구한 방법을 full gradient descent라 하고, 현실적으로 많이 사용되는 방법은 mini-batch 방법이 되겠다.
미니 뱃치는 속도와 효율성을 높이는 방법으로 training set의 일부만 사용해서 gradient을 계산하고, parameter을 업데이트해주는데, 계속 또 다른 training set의 일부를 이용해 parameter을 업데이트 하는 방법을 계속해서 반복하는 과정이다. 일반적으로 mini-batch사이즈는 32/64/ 128개의 사이즈을 가지게 되고 alex net에서는 256개의 minibatch을 사용했다.
이렇게 minibatch의 대표적인 방법으로 Stochastic Gradient Descnet(SGD)가 있다. 그리고 파라미터를 업데이트를 하는 방법으로 Adam, Adagrad, RMSprop, momentom가 있다. 하지만 SGD도 다른 방법들과 비교했을 시, 속도가 느린점이 있다.
기존 이미지 추출방식
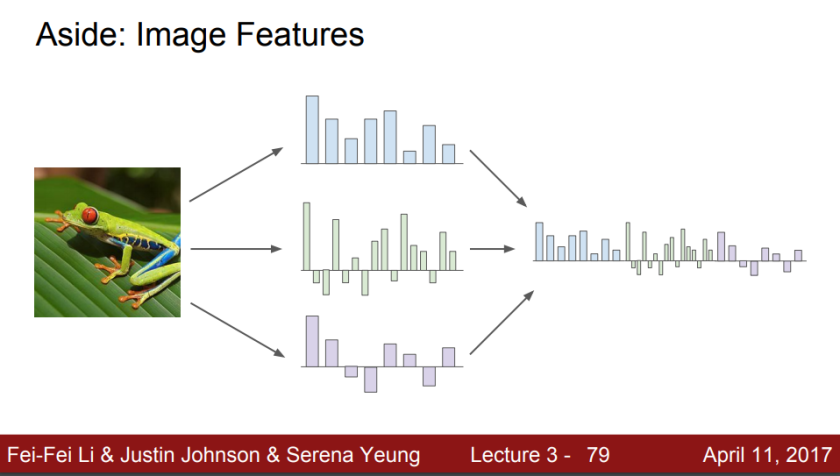
다음은 cnn을 하기전 일반적인 image classify을 어떻게 해왔는지 설명하겠다.
기존의 방식도 linearal classifier을 이용했지만 original image에다가 linear classify을 적용하지는 않았다. 단순 히스토그램이나 코드형태로 feature을 추출하고, 추출한 feature들을 concate하여 이어준다. 그 다음 linear clasifier에 적용했다. 이것이 일반적인 방법이었다.
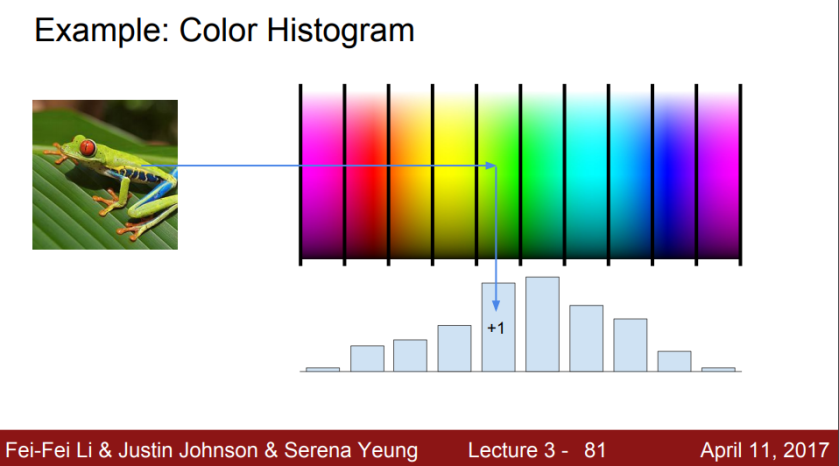
직선만으로 linear하게 구분하지 못한 한계가 있으니, 극좌표로 바꾸니 linear하게 구분할 수 있었고, 이에 영감을 받아 추출한 방법이 color histogram이다. color histogram은 이미지 내의 컬러를 모두 픽셀로 파악하고, 그 컬러의 픽셀을 전체 파노라마에서 color bin이 몇개인지 갯수를 세어 feature를 추출하는 방식이다.
두번째 feature를 추출하는 방식은 Histogram of Oriented Gradients(HoG) 이다.
8*8 픽셀로 구성된 구역을 총 9가지의 엣지의 bin으로 나눠서 9가지의 bin에 몇개가 속하는는지, edge의 의존도을 추출해낸 것이다.
세번째 feature를 추출하는 방식은 Bag of Words가 있다. 이 방법은 연어처리에서 자주 사용되는 기법인데,
이미지의 여러 지점들을 보고 이 작은 지점의 patch를 frequency 혹은 color의 vector로 기술하게 된다.
그래서 이것을 사전화해 사전내에서 test할 이미지와 가장 유사한 feature vector을 찾는다. 찾는방법은 K-means를 사용하는데, 이 feature vector을 찾고 이을 concatenation해서 linear classify을 한 방법이 된다.
이처럼 기존의 방식은 임의적으로 feature extraction을 통해 이미지를 분류지만, 다음시간부터 배울 딥러닝은 function에 넣어 스스로 특징을 추출하는 방식이다.
: 컴퓨터 비젼의 가장 핵심 과업이라고 할 수 있다. 예를 들어, 인풋 이미지로 고양이를 컴퓨터가 받는다면, 컴퓨터는 정해진 카테고리와 라벨들 중에서 골라낸다. 정해진 카테고리에서 골라 구분하는 작업이 인간에겐 매우 쉽게 느껴지지만, 컴퓨터에겐 전혀 그렇지 못한 문제이다. 컴퓨터 입장에서의 고양이 사진은 그저 수많은 픽셀이 들어있는, 거대한 숫자 격자로 표현된다.
하지만, 당연하게도 거대한 숫자 격자에서 ‘고양이다움’을 뽑아내긴 매우 힘들다. 인간은 고양이 사진을 보고 머릿속에서 categorize & label 작업이 가능하지만, 기계에게는 그저 숫자 정보일 뿐이므로 단번에 고양이라고 판별할 수가 없다. 바로 이 지점에서 우리가 한 번쯤은 들어봤을 개념인 “Semantic gap”이 발생한다. 코딩시 high level 언어에서 사용자의 편의성을 위한 기능과 low level에서 처리하고 있는 프로세서 간에 생기는 그 gap이다. 완전히 같은 의미로 표현한 것인지, 비슷한 맥락으로 표현한 것인지는 모르겠지만, 유사한 느낌으로 이해하면 될 것 같다.
이런 semantic gap이 발생하는 요인은 여러가지가 있다.
1) Viewpoint variation : 고양이 사진에서, 만약 고양이가 움직이지 않더라도, 카메라가 다른 방향에서 고양이를 찍게 된다면 모든 픽셀, 그리드가 완전히 달라질 것이다.
2) Illumination : 같은 고양이지만, 고양이가 받는 조명과 빛의 상태에 따라서, 컴퓨터가 인식하기엔 완전 다른 사진으로 느껴질 것이다.
3) Deformation : 고양이가 다양한 여러 포즈를 취하더라도 같은 고양이지만, 컴퓨터 인식상으론 다른 사진이다.
4) Occlusion : 인간은 고양이가 물체에 가려 있어도 인식가능하지만, 컴퓨터에겐 꽤 어려운 과제이다.
5) Background clutter : 고양이가 뒷 배경이랑 비슷할 경우, 인식에 문제가 있다. 인간은 충분히 인지 가능하더라도, 기계는 그렇지 않다.
6) Intraclass variation : 고양이들은 서로 다른 고유의 모양과 색, 나이, 크기를 가진다. 이 역시 컴퓨터에겐 꽤 어려운 문제이다.
컴퓨터는 위의 문제들을 동시에 처리 해야한다. 따라서 필요한 것이 바로 “Data-Driven Approach”이다. 이 방식은
1) 이미지와 라벨들의 데이터셋을 수집한다.
2) 분류기(Classifier)를 훈련시키기위해 머신러닝을 사용한다.
3) 새로운 이미지들에서 분류기를 평가한다.
물체에 관해서 하나하나 설명할 수 없음을 위의 Semantic gap 에서 알게 되었으니, 많은 양의 데이터셋을 이용해서 분류기를 만들어 내는 것이다.
따라서 훈련 함수와 예상 함수가 필요해졌다. 많은 데이터를 통해 훈련시킨 모델로 예상하는 구조가 Data-Driven Approach라 할 수 있겠다.
2. Classifier
그렇다면 기초적인 분류기들은 무엇이 있을까.
2-1. KNN (k-nearest neighbor)
첫 번째로 설명할 분류기는 Knn이다. 흐름을 알아야 이해가 편하기에, 강의의 순서를 조금 바꿔 요약본 부터 보고 가자. KNN은 가까이에 있는 훈련 이미지 예시들에 근거해서 라벨을 예측한다. 더 정확한 예측을 하기 위해선 필요한 것들이 바로 Distance metric과 K 값 인데,Hyperparameters라고 칭한다. Hyperparameters는 ‘proble-dependent’의 성격을 가지고 있기에, Validation 셋에서 여러가지 시도해보고 가장 좋은 포인트를 찾는 과정이 필요하다.
2-1-1) Value of K
KNN은 가까이에 있는 이미지들 끼리 비교해서 예측하는 과정이라고 언급했듯, 위의 그림을 보면, 그 과정을 볼 수 있다. k=1 일때란, 각 좌표가 근처 이웃 1개만큼이랑 비교하여 카테고리를 나누었다. 하지만 눈으로 확인 가능하듯, 분류선이 삐죽삐죽하거나, 한 레이블 안에 다른 레이블이 들어가 있는 등 단점이 있다. 따라서 개선한 것이, K개 만큼의 가까운 이웃과 비교하여 가장 많은 레이블에 속한 레이블로 투표 하여 정하는 방법이다. 확실히 k 가 1일때 보다는 훨씬 결정 경계가 완만하고 예측 결과가 좋기 때문에 k는 1이상을 사용한다.
2-1-2) Distance metric
Value of K 에서 , 각 좌표가 주변의 좌표와 비교하는 과정이 필요하다고 했었다. 즉, 테스트 군과 훈련 군을 비교하는 방법을 말하는 것인데, 그렇다면 이 비교하는 과정은 어떤 방식으로 하는 것인지 알아보자.
위 사진은 L1 방식에 대한 설명이다. 간단히 , 픽셀화된 테스트 이미지에서 트레이닝 이미지 수치를 뺀 것의 절대값을 모두 합하여 결과를 내는 방식이다. 위 예시에서는 456만큼의 거리가 있다고 계산한 것이다.
이 강의에서 배운 Distance metrics 는 총 2가지로 L1 방식과 L2방식이다. L1방식은 위에서 설명한 방식, L2 방식은 테스트군 – 훈련군을 제곱한 것의 합에 대한 제곱근을 구하는 방식이다. 위의 그림에서 알 수 있듯이, L1 방법과 L2 방법은 구조가 다르다. 그렇다면 무슨 차이가 있을까?
결정적인 차이는 좌표계와 연관성이다. L1 방식은 좌표계가 돌아가면 모양도 달라진다. L2 방식은 돌아가도 모양에 아무 변화가 없다. 따라서 L1방식은 특징 벡터의 요소가 실질적인 의미를 가질 경우, L2 방식은 특징 벡터의 요소가 일반적이고 실질적인 의미를 모를 때 사용한다.
2-1-3) Hyperparameters
위에서 배운, Value of K와 Distance metrics 를 최적으로 설정하는 것을 Hyperparameters 라고 한다. 여기서 Value of K 와 Distance Metrics가 최적인 경우란, 트레이닝 데이터셋의 정확도가 최대화 되는 경우를 의미한다. summary에서 말했듯, 최적을 찾으려면 이것저것 시도해보는 방법 밖에 없다. 따라서 아래 ideas를 보자.
1) k 가 1 일 경우에는, 자신의 데이터셋에서는 효과가 좋을지 몰라도 새로운 데이터에는 효과가 없다.
2) 트레이닝 과 테스트 데이터 셋으로 나누는 방법인데, 이 역시 1번과 마찬가지이다.
3) 트레이닝 데이터셋 , 평가 데이터셋, 테스트 데이터셋으로 나누는 방법이다. 트레이닝 셋에서 학습을 시키고, 평가 셋에서 검증, 마지막으로 테스 트 셋에서 1번만 실행하는 방식이다.
4) 교차 검증방식이다. 데이터셋을 수많은 split-data로 나누어, 나누어진 fold들을 각각 1번씩 평가 데이터 셋으로 설정하여 진행하는 방식이다.
효과는 좋지만, 계산량이 너무 많아지는 단점이 있어 실용적이진 않다.
2-1-4) KNN의 단점
KNN은 실제로 잘 사용되지 않는다. 그 이유로는 몇가지가 있는데, 우선 너무 느리다. 또한, 이미지간의 perceptual similarity을 잘 인지하지 못한다. 또한, KNN방식은 이웃간의 비교를 통한 방식이므로, 이 ‘이웃'(데이터)들이 서로 밀접하여야 한다. 따라서 차원이 증가할 수록, 그 공간을 ‘이웃’들이 가득 메워야 하므로 필요한 이웃들이 굉장히 많아진다. 따라서 KNN을 사용하기 위해 필요한 데이터가 너무 과하게 많아지는 문제가 생기기 때문이다.
2-2. Linear Classification
두 번째 분류기(Classifier)는 바로 선형(Linear) 분류기이다. 선형 분류기는 parametic model 중 하나이다. 선형 회귀 모델에서는 3가지 요소를 알아야한다. 바로 입력값 X, 가중치 W , 바이어스 B이다.
입력값에 가중치를 곱하여, bias 를 더해주어 나오는 결과값을 통해 입력 데이터가 어떤 클래스인지 확인하는 방식이다. 여기서 bias란, 데이터 셋에 불균형이 존재할 때, 이를 커버하기 위해 더해지는 값이다.
밑의 사진들은 각 클래스들의 템플릿 이미지이다. 선형 모델은 데이터들을 평균화 하여 템플릿을 만들기 때문에 , 완전 정확한 템플릿이 아닐 수도 있다. 예를 들어, horse템플릿을 보면, 말이 머리가 2개인 템플릿이 완성되었다.
하지만 이러한 linear 분류기로도 애매한 케이스들이 존재한다.
선형 모델이란 결국, 데이터를 분류해주는 가장 정확한 선을 긋는 과정인데, 위의 경우들을 보면 선 하나를 긋는 것으로는 절대 불가능하다는 것이다. 따라서 이를 보완하기 위한 방법들이 존재한다.





















































![39편] 인공신경망/AI에 대한 간략한 히스토리 : 네이버 블로그](https://lh3.googleusercontent.com/proxy/3JhCDeOrB9-mTFPVHFuypSpGuma7HecofCnU7wVd_u56JAcrLQpApv-SD2RwiGWArjt_kRAEQMnw6gtvwiVmUhFBoK1yUOqoqoxE8s8iHsq7MhRvyv2MsREyDAdxroOEe0l3WW954p1d6OJf7YLWMP1v_47BOUZRNPx3MKiCOsJhzrccJVEQ4MeoU1NXEVrar9-Q1BXrmwAhcF0p-041698QuvMLrFykQ9LZquWD8MPM3kBIWIFRgH_zIbMwDa-ecDzriOrLZvG69aSXygkm9ACZAhJrWapDuGoTK7N8rP8w7FjxH8uAHg)
![PyTorch tutorial] 컴퓨터 비전(Vision)을 위한 전이학습(Transfer Learning)](https://blog.kakaocdn.net/dn/ZkO4f/btqD6mFGYN3/R0GpC1kOFBQuvO3YlK6V20/img.png)


